
🏗️ Cloud e IaC: Do console da AWS ao script versionado
Nos artigos anteriores, preparamos o pacote (Docker), definimos a entrega (CI/CD) e a estratégia de deploy (Blue/Green). Mas isso tudo vai rodar onde?
A resposta óbvia é “Na Nuvem”. Mas “Nuvem” não é apenas um computador alheio. Em grandes empresas, a infraestrutura deixou de ser um lugar físico para se tornar código.
Se o seu servidor cai às 3 da manhã, você não quer depender de um herói que sabe de cabeça o IP de alguma máquina virtual. Você quer um script que reconstrua o universo em minutos. Hoje vamos falar sobre a Infraestrutura Invisível.
1. O Cardápio da Nuvem: Onde meu código vive?
Antigamente, a decisão era comprar servidor Dell ou HP, conexão com internet, segurança física, entre outros. Hoje, a decisão é sobre o nível de abstração. Quanto mais abstração, menos gerenciamento.
- IaaS (Infrastructure as a Service) – A Locadora: Você aluga a máquina virtual (EC2 na AWS, VM no Azure). O SO é problema seu. Atualizar o Linux é problema seu. Instalar o Docker é problema seu.
- CaaS (Container as a Service) – O Padrão da Indústria: Aqui vivem o Kubernetes (EKS/AKS/GKE) e o ECS. Agora não é mais gerenciar a máquina, é gerenciar o Cluster. Você diz: “Quero 10 containers com 2GB de RAM”. A nuvem se vira para achar onde rodar. É aqui que a maioria das grandes empresas opera hoje.
- PaaS & Serverless – O Uber: Você não precisa se preocupar como o código vai rodar, onde ou se existe servidor. Você entrega o código e a nuvem executa. Exemplos: AWS Lambda, Azure Functions, Google Cloud Run.
2. Infrastructure as Code (IaC): O Fim do “ClickOps”
Aqui reside a maturidade da gestão de infraestrutura.
Imagine que você precisa criar um banco de dados, duas filas SQS e um bucket S3. Então temos duas possibilidades:
- Cenário #01: Logar no console da AWS, clicar em “Create S3”, escolher um nome, ajustar parâmetros, clicar em “Next, Next, Finish”.
- O Cenário #02: Escrever um arquivo de roteiro para a construção da infraestrutura, em formato texto.
O Cenário #01 é conhecido como ClickOps (operações via clique). Toda a operação no processo de criação, teste de cenários, de novas possibilidades e substituição e ajustes de serviços vai passar inevitavelmente pelo ClickOps, configurando, derrubando e levantando novos serviços pelo painel.
Mas quando a operação cresce, se torna crítica e mantém estabilidade arquitetural por mais de alguns dias, a única forma de manter, recuperar desastres e operar entregas contínuas é utilizar o método de Infraestrutura como Código (IaC). Por quê?
O método ClickOps funciona no início de uma operação ou startup, mas tem suas limitações:
- Sem Rastreabilidade: Quem criou aquele bucket aberto para a internet? Quando? Por quê? O console não conta a história, ou conta pela metade.
- Irreprodutibilidade: Se precisarmos criar um ambiente de Staging igual ao de Produção, o humano vai esquecer de marcar uma caixinha e o ambiente vai quebrar (lembra do Configuration Drift?).
- Disaster Recovery: Se alguém apagar a conta da nuvem hoje, quanto tempo você leva para recriar tudo clicando?
A Solução: Terraform ou OpenTofu
Usamos ferramentas de IaC (Infrastructure as a Service). Você descreve o que quer em código:
resource "aws_s3_bucket" "meu_bucket" {
bucket = "app-logs-production"
acl = "private"
}Quando você roda esse código, a ferramenta compara o que você pediu com o que existe na nuvem e faz a mágica acontecer. O estado da sua infraestrutura fica versionado no Git. Infraestrutura agora é gerida como Software, ou mais adequadamente, como um script.
Sobre o AWS CloudFormation: É a ferramenta nativa da Amazon para implementar Infraestrutura como Código (IaC). Ele permite modelar e provisionar recursos da AWS — desde um simples bucket S3 até arquiteturas complexas de microsserviços — usando templates declarativos em YAML ou JSON. Ao definir o “estado desejado” da sua infraestrutura nesses arquivos, o CloudFormation automatiza a criação, atualização e gerenciamento de todo o conjunto de recursos (conhecido como stack) de forma ordenada e previsível, eliminando o “ClickOps” e garantindo que seus ambientes sejam consistentes e reprodutíveis. É uma solução nativa do AWS fortemente integrada a todos os seus serviços, e tem custo que deve ser contabilizado.
3. Alta Disponibilidade: Sobrevivendo a Terremotos
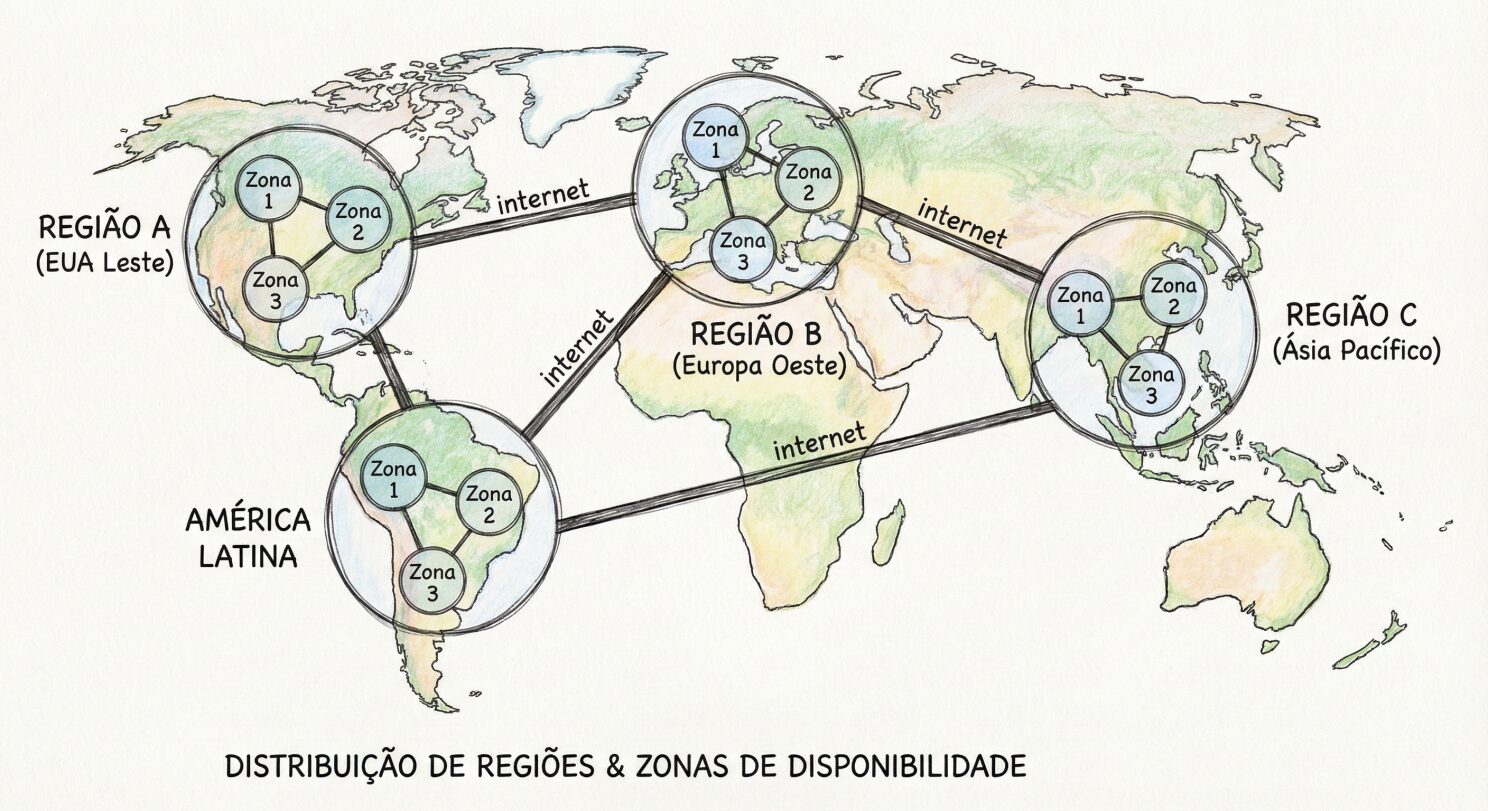
“O sistema caiu”. Em grandes empresas, a pergunta seguinte é: “Caiu o container, caiu a zona ou caiu a região?”
Para garantir 99,99% de disponibilidade (o “quatro noves”), trabalhamos com redundância geográfica:
- Multi-AZ (Availability Zones): Dentro da mesma região (ex: São Paulo), a AWS tem datacenters fisicamente separados por quilômetros (Zona A, Zona B, Zona C). Se um prédio pegar fogo ou ficar sem luz, o Load Balancer joga o tráfego para a Zona B. Em sistemas críticos, isso é o mínimo obrigatório para produção.
- Multi-Region (O Nível Global): E se um furacão atingir a Virgínia inteira? Ou se alguém cortar os cabos submarinos do Brasil? Empresas globais (Netflix, Uber) rodam em múltiplas regiões simultaneamente (ex: us-east-1 e sa-east-1).
Observações Importantes:
- Sincronizar um banco de dados entre Brasil e EUA em tempo real é fisicamente impossível sem latência. Arquiteturas multi-região (Active-Active) são complexas, caras e exigem bancos de dados globais (como DynamoDB Global Tables ou CockroachDB).
- As zonas de uma mesma região do AWS (e outros provedores) geralmente são conectadas diretamente por fibra ótica, e dados trocados entre as zonas não trafegam pela internet pública, o que em geral não gera custo extra. Dados trafegados entre regiões diferentes utilizam a internet e geram custos.
🏁 Resumo da Etapa
A infraestrutura moderna não forjada em painéis clicáveis, é feita de texto. Aprendemos que a “Nuvem” tem um cardápio variado (de IaaS a Serverless) e que a escolha errada pode custar caro (seja em gerenciamento, em Cold Starts ou distribuição em regiões). Mais importante: decretamos o fim do ClickOps em ambientes críticos. Se a sua infraestrutura não está descrita em um arquivo (Terraform/OpenTofu) e versionada no Git, ela não existe, é apenas uma alucinação temporária no console da AWS. Por fim, entendemos que disponibilidade é física: usar Multi-AZ é o seguro de vida básico contra falhas locais, enquanto Multi-Region é a complexa (e cara) proteção contra catástrofes globais.
⏭️ No próximo artigo: Temos a infraestrutura de pé e o código rodando. Mas como sabemos se o usuário está feliz ou recebendo erros? Vamos falar sobre Observabilidade (não confundir com Monitoramento básico). Logs, Métricas e Tracing: os olhos e ouvidos do engenheiro.
Deixe um comentário