
🚀 Deploy não é Release: A arte de entregar software sem suar frio
No artigo passado, a Integração Contínua garantiu que o código está limpo, testado e seguro. Mas código parado no repositório não gera valor, ele precisa trabalhar para sua empresa.
É aqui que muitas empresas travam. O medo de subir uma alteração e derrubar o sistema faz com que os deploys sejam eventos raros, tensos e agendados para a madrugada.
Grandes empresas como Netflix, Amazon e Google fazem milhares de deploys por dia. Como? Elas mudaram duas coisas fundamentais: o formato do pacote e o conceito de entrega.
1. Artifacts e Docker: O Pacote Imutável
Antigamente, fazer deploy significava entrar no servidor via FTP ou SSH, puxar arquivos soltos, rodar um npm install lá dentro e rezar para a versão do Node ser a mesma da sua máquina – é a receita para o desastre (o famoso Configuration Drift).
Em ambientes profissionais, adotamos o Build Once, Deploy Anywhere (Construa uma vez, implante em qualquer lugar).
Quando o CI termina os testes, ele gera um Artefato. Hoje em dia, esse artefato é quase sempre uma Imagem Docker.
- O Conceito: Imagine que você “congelou” não só o seu código, mas também o sistema operacional, as bibliotecas e as configurações num pacote fechado e lacrado.
- Imutabilidade: Essa imagem gerada no CI nunca mais é alterada. A imagem que rodou no ambiente de Testes (QA) é exatamente a mesma que vai para Pré-Produção e para Produção.
- O Resultado: Acaba a incerteza. Se funcionou e passou nos testes, vai funcionar em produção, porque o ambiente vai junto com o código.
⚠️ Importante: a imagem deve ser sempre Stateless (Sem Estado). Para que essa mágica funcione, temos que ter ciência de que o container é efêmero. Ele nasce e morre sem deixar rastros.
- Isso significa que a aplicação não guarda dados nela mesma.
- Uploads de usuários (PDFs, fotos)? Vão para um Object Storage externo (S3, Azure Blob).
- Sessões de login? Vão para um Redis externo (ou Memcache, ou outro DB).
- Dados de negócio? Vão para o Banco de Dados externo, preferencialmente gerenciado como RDS.
- Se o container explodir agora, não perdemos nada. Basta subir um novo.
Essas imagens ficam guardadas em uma espécie de depósito chamado Container Registry (AWS ECR, Docker Hub, etc.), prontas para serem chamadas.
2. Deploy vs. Release: Duas Coisas Diferentes
Aqui está o plot twist mental. No imaginário geral o Deploy e o Release são sinônimos. Só que não são.
- 🚚 Deploy (Implantação): É uma ação técnica. É instalar a nova versão do artefato na infraestrutura. O código novo está lá no servidor, consumindo memória, ligado ao banco de dados, mas… ninguém está usando.
- 🎉 Release (Lançamento): É uma ação de negócio. É o momento em que a funcionalidade fica disponível para o utilizador final.
Por que separar? Porque Deploy é arriscado, mexe nos servidores, mas o Release deve ser estratégico. Se você faz os dois ao mesmo tempo, qualquer problema técnico vira um desastre de negócio imediato. Ao separar, você pode fazer o deploy numa terça-feira à tarde, verificar se o servidor aguentou e as coisas funcionaram, e só liberar a funcionalidade na quarta-feira de manhã.
Existem duas formas principais de realizar esse Release:
- Via Infraestrutura: Ajustando o Load Balancer para começar a enviar tráfego para os novos containers (estratégias como Canary ou Blue/Green, que veremos em detalhes no próximo artigo).
- Via Aplicação: Usando lógica dentro do próprio código para ativar recursos. É aqui que entram as Feature Flags.
Nesse artigo vamos focar na segunda opção – Feature Flags – e deixar o Load Balancer para o artigo 4 (o próximo), onde nos aprofundaremos nos aspectos de delivery via infraestrutura.
3. Feature Flags: A Mágica
Como fazemos essa separação na prática? Como o código pode estar no servidor, “vivo”, mas o usuário não ver?
Usamos Feature Flags (ou Feature Toggles). Na sua forma mais simples, é uma condicional (if/else) no código, mas com um impacto poderoso: a decisão de entrar no if ou no else não é fixa (hardcoded), ela vem de um painel de controle externo em tempo real.
// Exemplo conceitual
const flags = await featureService.getFlags();
if (flags.isEnabled('novo-checkout-v2')) {
// Nova funcionalidade (código novo)
return <NewCheckoutFlow />;
} else {
// Funcionalidade antiga (código atual)
return <OldCheckoutFlow />;
}Parece trivial, mas essa pequena estrutura muda completamente a dinâmica da engenharia:
- Trunk Based Development (O Fim das Branches Longas): Lembra do Artigo 1? Com Flags, você pode fazer o merge de um código incompleto para a main. Basta envolver o código novo nessa condicional e manter a flag desligada (false) no painel. O código vai para produção, reside no servidor, mas é invisível para o usuário. Isso elimina o inferno de manter branches abertas por semanas.
- Kill Switch (O Botão de Pânico): Imagine que você lançou o novo checkout e, 10 minutos depois, descobre um bug crítico que impede as vendas. Aperte o botão e retroceda a flag.
- Testes em Produção (Segmentação): O ambiente de staging nunca é igual ao de produção (pode ser igual em ambiente e código, mas difere em dados, massa de usuários, etc). Com flags, você pode ligar a nova funcionalidade apenas para usuários internos (identificados, por exemplo, pelo e-mail @suaempresa.com). O time testa a feature no ambiente real, com dados reais, enquanto o cliente final continua vendo a versão antiga.
🛠️ O Arsenal: Escolhendo sua ferramenta de Flags
Já vi em alguns projetos (grandes) uma tabela no banco de dados chamada features. Cuidado, isso não escala. Ferramentas profissionais lidam com cache (para não matar o banco a cada F5 de um usuário em outro continente), segmentação complexa e audit logs.
O mercado divide-se basicamente em dois grupos:
a) As Nativas de Nuvem (Cloud Native)
Se a sua empresa já está casada com um provedor de nuvem, usar as ferramentas nativas é geralmente mais barato e seguro (já integrado ao IAM, etc).
- AWS AppConfig (parte do Systems Manager): Não serve apenas para flags, mas para qualquer configuração dinâmica. É extremamente robusto e permite deploy gradual da configuração (ex: liberar a flag para 10% dos servidores a cada minuto).
- Azure App Configuration: Tem um gerenciador de features (Feature Manager) nativo excelente, com interface gráfica simples para ligar/desligar.
- Google Cloud (Firebase Remote Config): Embora o Google Cloud tenha o Runtime Configurator, o padrão de mercado no ecossistema Google (especialmente para Mobile e Front-end) é o Firebase Remote Config é imbatível para segmentar usuários (ex: ligar flag apenas para usuários Android no Brasil…).
b) As Especialistas (SaaS & Open Source)
Estas ferramentas são agnósticas de nuvem. São ideais se você usa Multi-Cloud ou se quer uma interface mais amigável para que Gerentes de Produto (PMs) mexam nas flags sem precisar logar no console da AWS.
- LaunchDarkly: É a líder de mercado, cheia de recursos visuais, testes A/B complexos e integrações. O custo é maior, mas para projetos grandes e críticos paga-se sozinha pela estabilidade.
- Unleash: É livre e open source (Apache License). Você pode pagar pelo serviço hospedado ou baixar o Docker deles e rodar nos seus próprios servidores (self-hosted). Popular em empresas que querem privacidade total dos dados.
- Flagsmith: Outra excelente opção livre e open source (BSD License), focada na experiência do desenvolvedor. Simples, direta e eficaz.
💡 Construir ou Comprar?
Uma regra simples em grandes empresas é: Não reinventar a roda.
Construir um sistema de feature flags caseiro parece fácil no dia 1. Mas no dia 300, quando você precisar garantir que a flag atualize em 50 milissegundos em servidores distribuídos globalmente sem derrubar o banco de dados, você vai desejar ter usado uma ferramenta pronta.
Comece simples (talvez com Unleash self-hosted ou a nativa da sua nuvem), mas evite hardcode no banco de dados.
⚠️ Dica de Experiência:
- Feature Flags geram débito técnico. Se você encher o código de if/else e nunca limpar, o sistema vira um espaguete. A regra é: lançou, validou que está estável? Remova a flag e o código antigo na sprint seguinte. Os gestores técnicos deve estar atento a isso.
- Busque padrões usados no mercado de Feature Flags para cada ferramenta, ambiente, framework e/ou linguagem, tem coisa já testada e elegante pronta pra uso, e as vezes é um simples if/else mesmo.
🚎 O Fluxo Completo
Agora já temos um caminho desde o código na máquina do dev até a produção:
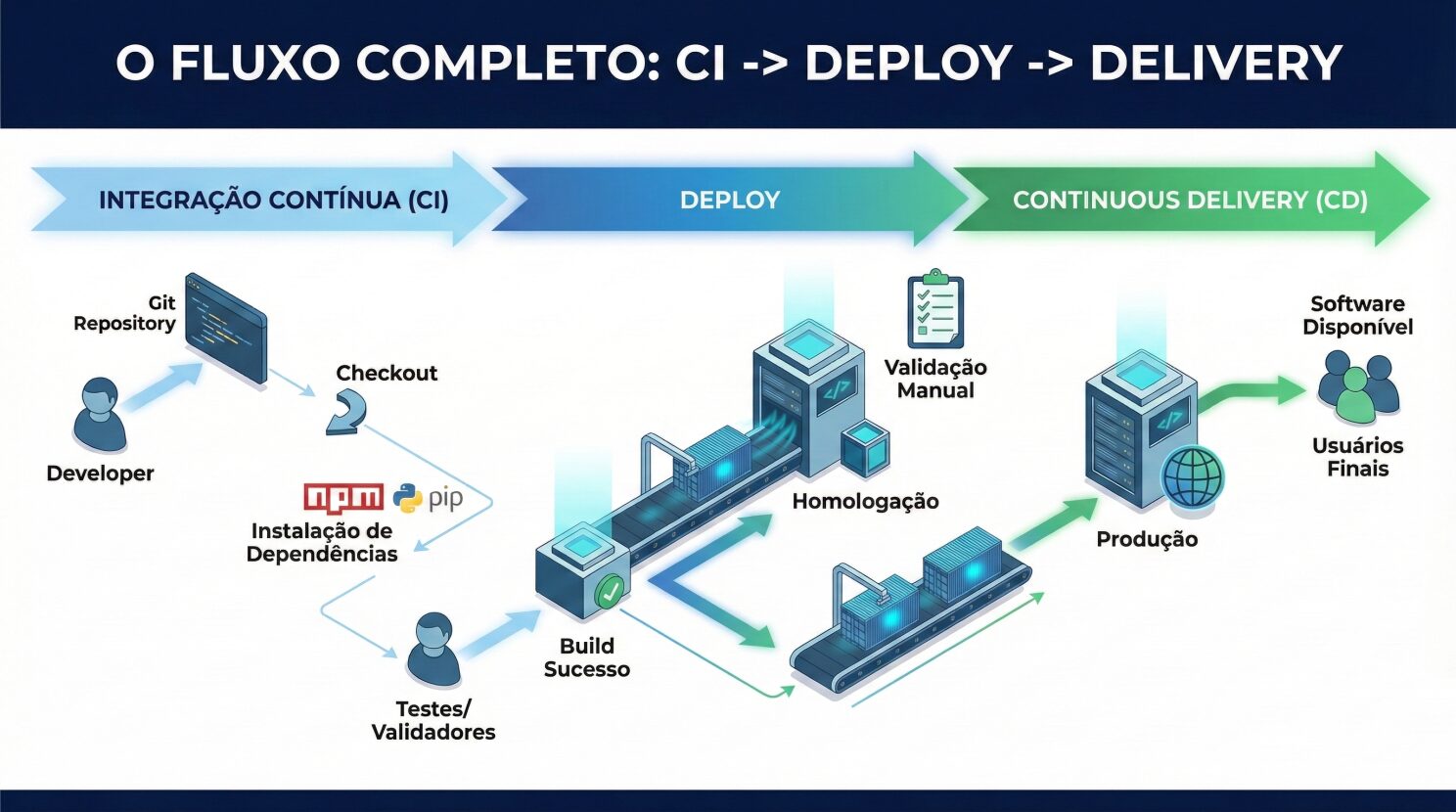
Nos próximos artigos seguiremos refinando isso tudo, apontando estratégias para deploy sem downtime, infraestrutura, observabilidade e segurança.
🏁 Resumo da Etapa: Transformamos o Deploy de um monstro imprevisível num processo rotineiro de mover caixas (containers). O código está lá, seguro, encapsulado e dormindo atrás de uma Feature Flag.
⏭️ No próximo artigo: Já sabemos como criar o pacote e como esconder a funcionalidade. Mas como fazemos a troca da versão v1 para a v2 com milhares de usuários online, sem que ninguém receba um erro 500? Vamos falar de Estratégias de Deploy Zero Downtime (Blue/Green, Canary e Rolling Updates, etc).
Deixe um comentário