
Olhando a Caixa Preta: Como saber se o sistema está saudável (e não apenas “de pé”)
Nos últimos cinco artigos, construímos uma esteira de entrega de classe mundial. Temos CI/CD, containers Docker, estratégias de deploy Blue/Green e infraestrutura como código. O sistema está rodando na nuvem em múltiplas zonas de disponibilidade.
Tudo parece perfeito. Até que um cliente reclama no Xwitter: “O checkout está lento e dando erro 500”.
Você abre o painel da AWS. Todos os servidores estão verdinhos (“Health Check: OK”). O uso de CPU está baixo. A memória está ok.
Seja bem-vindo ao pesadelo dos sistemas distribuídos. Em um monólito antigo, se algo quebrava, você (eu…) abria uma conexão SSH na máquina e lia o arquivo de log. Hoje, uma única transação de compra pode passar por 15 microsserviços diferentes, filas SQS, PubSub, e dois tipos de banco de dados. Onde está o erro?
Se você não consegue responder a essa pergunta, você não tem um sistema, você tem uma “Caixa Preta”.
E é aqui que profissionalizamos a engenharia. Saímos do simples Monitoramento (“O servidor está ligado?”) para a Observabilidade (“Por que o servidor está lento?”).
1. Os Três Pilares da Observabilidade
Para entender um sistema complexo sem precisar abrir o capô a cada minuto, precisamos de três tipos de dados fundamentais.
🔍 1º Pilar: Logs (O “O que aconteceu?”) Logs são o diário de bordo da sua aplicação. É o registro narrativo dos eventos.
- O Erro Comum: Logs cheios de console.log(“cheguei aqui”) ou textos soltos que só humanos (ou especificamente quem programou) entendem.
- A Abordagem Profissional: Logs Estruturados (JSON). Em vez de uma frase, o log é um objeto JSON com chaves e valores (user_id, order_id, erro_code, timestamp). Isso permite que máquinas indexem e busquem logs como se fossem um banco de dados.
📈 2º Pilar: Métricas (O “Qual é a tendência?”) Se o log é um evento pontual, a métrica é uma medida numérica ao longo do tempo.
- Exemplos: Uso de CPU, consumo de memória RAM, quantidade de requests por segundo (RPS), tempo médio de resposta.
- O Valor: Métricas mostram a saúde geral. Elas não dizem qual usuário teve erro, mas dizem que “a taxa de erros subiu de 0.1% para 5% nos últimos 10 minutos”.
📍 3º Pilar: Tracing Distribuído (O “Onde aconteceu?”) Este é o pilar mais difícil e mais valioso em microsserviços. Quando o usuário clica em “Comprar”, um Trace ID (um código único) deve ser gerado no frontend. Esse ID viaja no cabeçalho HTTP de cada requisição interna: do Serviço A para o B, do B para o Banco, do B para a Fila C.
- O Valor: Ferramentas de tracing desenham um mapa. Você vê que a requisição total levou 2 segundos, e que 1.8 segundos foram gastos no banco de dados de estoque. Sem isso, achar gargalos de performance fica no âmbito da adivinhação.
2. O Arsenal de Ferramentas e a Agregação
Ninguém faz isso na mão. O ecossistema de observabilidade é vasto:
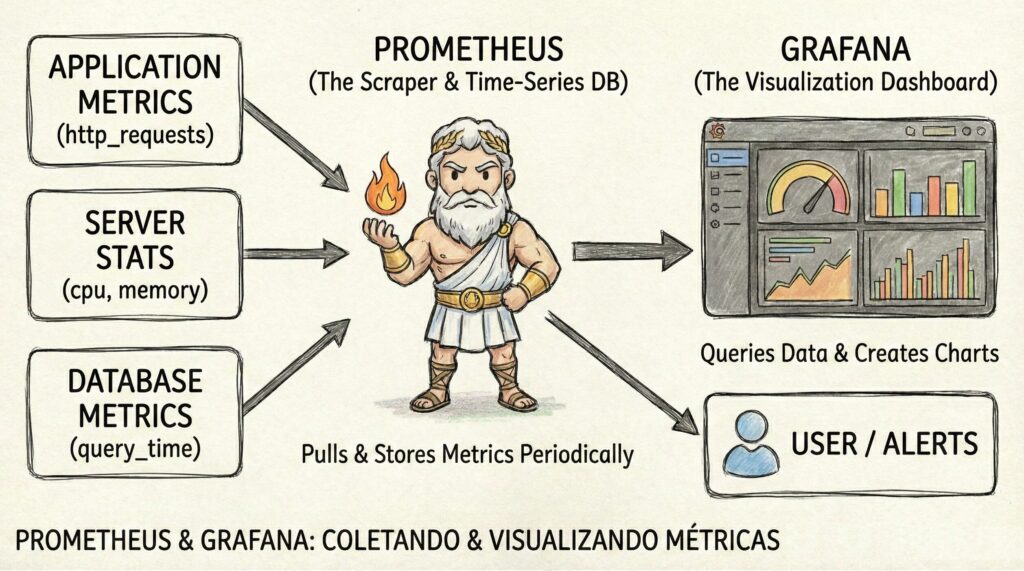
- O Cenário Self-Hosted (DIY / Faça Você Mesmo): Aqui você não paga licença de software, mas paga com o tempo da sua equipe para configurar e gerenciar os servidores. A dupla muito utilizada é o Prometheus (coleta) e Grafana (visualização). O Prometheus coleta métricas e estatísticas dos servidores de aplicação e DB e envia alertas e dados mastigados para visualizar no Grafana. Para logs, o clássico é o ELK Stack (Elasticsearch, Logstash, Kibana) ou sua alternativa 100% open-source, o OpenSearch. Uma opção mais moderna e leve para logs que vem ganhando espaço é o Grafana Loki.
- O Cenário SaaS (Plataformas Gerenciadas): Ferramentas como Datadog, New Relic e Dynatrace oferecem os três pilares integrados “fora da caixa”. Dependendo do tamanho da empresa, número de requisições e complexidade do projeto podem ficar caras, mas você terceiriza as dores de cabeça de manter a infraestrutura de pé e podem economizar centenas de horas de configuração e possivelmente contratação(ões) para manter a infra.
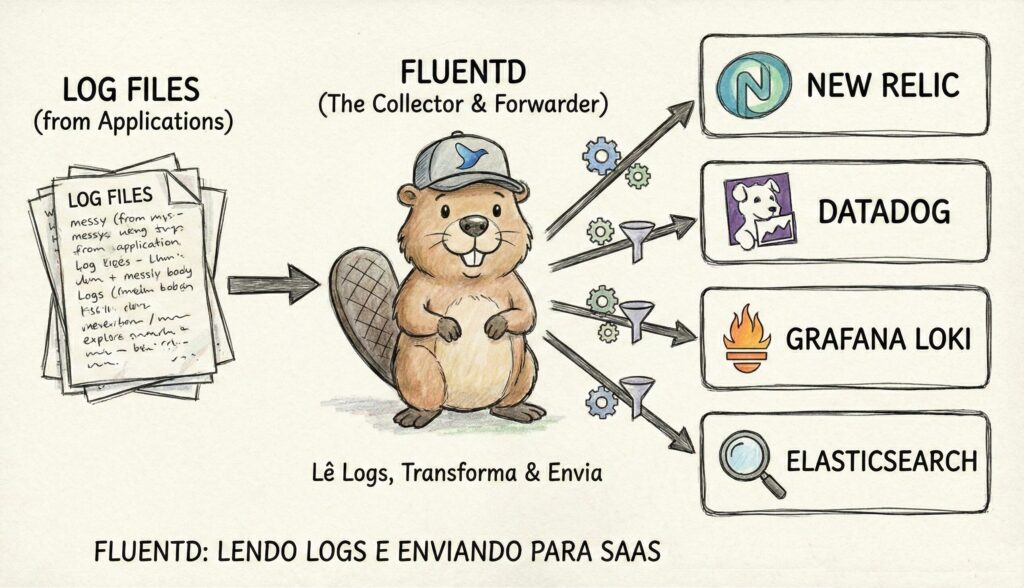
O Problema dos Containers Efêmeros e a Solução (Fluentd): Lembra que no Artigo 3 dissemos que containers nascem e morrem? Se o seu aplicativo grava logs num arquivo local dentro do container, quando o container morre, o log morre junto. A solução é usar Agentes Coletores (como Fluentd ou Logstash). Eles rodam como um “sidecar” (um container auxiliar) que pega o log da sua aplicação e o envia imediatamente para um storage centralizado (Elasticsearch, S3, New Reilic, etc) antes que o container desapareça. Eles são compatíveis com a maioria das plataformas através de plugins.
3. Alerta Inteligente: Pare de acordar às 3 da manhã à toa
Tendo os dados, o próximo passo é configurar alertas. Aqui acontece o maior erro cultural das equipes de operações: a “Fadiga de Alertas”.
Se o seu celular apita toda vez que a CPU de um servidor passa de 80%, você vai começar a ignorar os alertas. CPU alta não é necessariamente um problema; pode ser apenas o sistema trabalhando bem no horário de pico.
A regra: Alerte sobre Sintomas, não sobre Causas.
- Alerta Ruim (Causa): “O servidor DB-01 está com 90% de CPU”. (O usuário final não liga para a CPU do seu banco).
- Alerta Bom (Sintoma): “A taxa de sucesso do checkout caiu para 95%” ou “O tempo de resposta da API de login passou de 2 segundos”.
O sintoma indica dor real do cliente. Quando o sintoma aparece, aí sim o engenheiro usa os dashboards de CPU e Memória (Causas) para investigar.
🏁 Resumo da Etapa
Monitoramento é saber se o servidor está vivo. Observabilidade é entender por que ele está agindo de forma estranha, usando os três pilares: Logs (narrativa estruturada), Métricas (tendências numéricas) e Tracing (o mapa da requisição). E lembre-se: só configure alertas que indiquem dor real do usuário, ou seu time de SRE vai odiar o sistema de monitoramento.
Deixe um comentário