Trocar o Pneu com o Carro em Movimento: O fim do “Estamos em Manutenção”
Você lembra das telas de “Estamos em Manutenção – Volte mais tarde”? Em 2025, em projetos críticos com milhares de usuários, isso é inadmissível. Se a Amazon parar por 10 minutos para atualizar o sistema, milhões de dólares são perdidos. O sistema tem que estar up 24/7.

No artigo anterior, entendemos os conceitos de criar pacotes imutáveis (Docker) e a usar Feature Flags. Mas sobrou uma pergunta crucial:
“Como eu substituo a versão antiga (v1) pela nova (v2) nos servidores enquanto 50 mil usuários estão comprando no site, sem que ninguém receba um erro 500 na cara?”
A resposta não é código, é Orquestração de Tráfego. Não desligamos o antigo para ligar o novo; fazemos uma transição coreografada. Existem três estratégias principais para isso, e a escolha depende do tamanho do caixa e/ou da aversão ao risco.
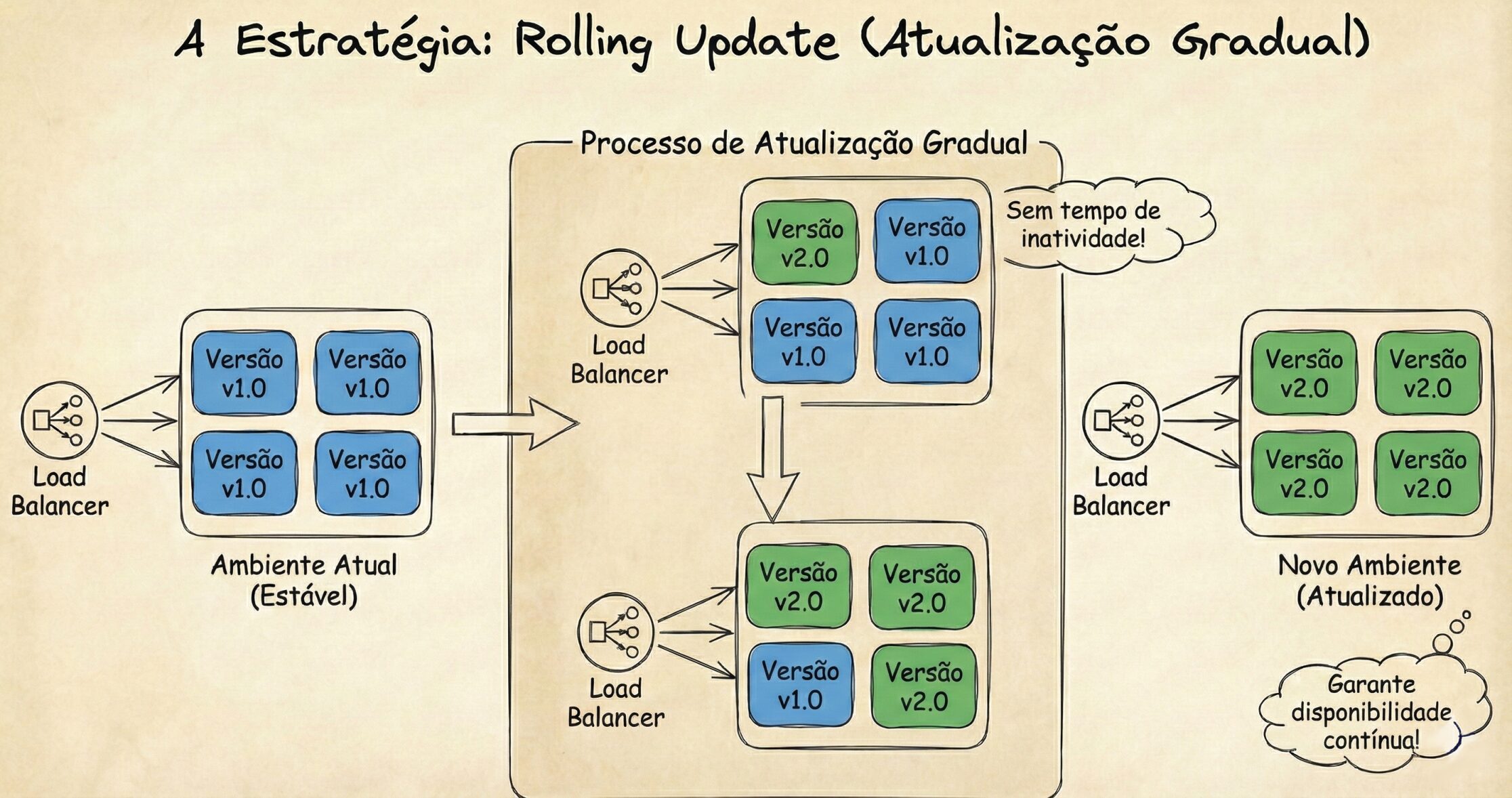
1. Rolling Update: O Padrão Econômico
Se você usa Kubernetes “out-of-the-box” (o padrão de fábrica do Kubernetes), é provável que esteja usando esta estratégia.
Como funciona: Imagine 10 containers rodando a versão v1. O orquestrador não mata todos de uma vez. Ele mata um container antigo e sobe um novo. Espera o novo ficar saudável (“Health Check ok”) e parte para o próximo. O processo se repete até que todos os 10 estejam na v2.
Vantagem: É barato. Você só precisa de recursos extras para suportar uma instância adicional durante o processo (o famoso maxSurge).
O Risco: O Rollback é lento. Se você descobrir um bug crítico quando 50% dos containers já foram atualizados, terá que esperar o processo inverso acontecer um por um. Durante esse tempo, metade dos seus usuários verá o erro.
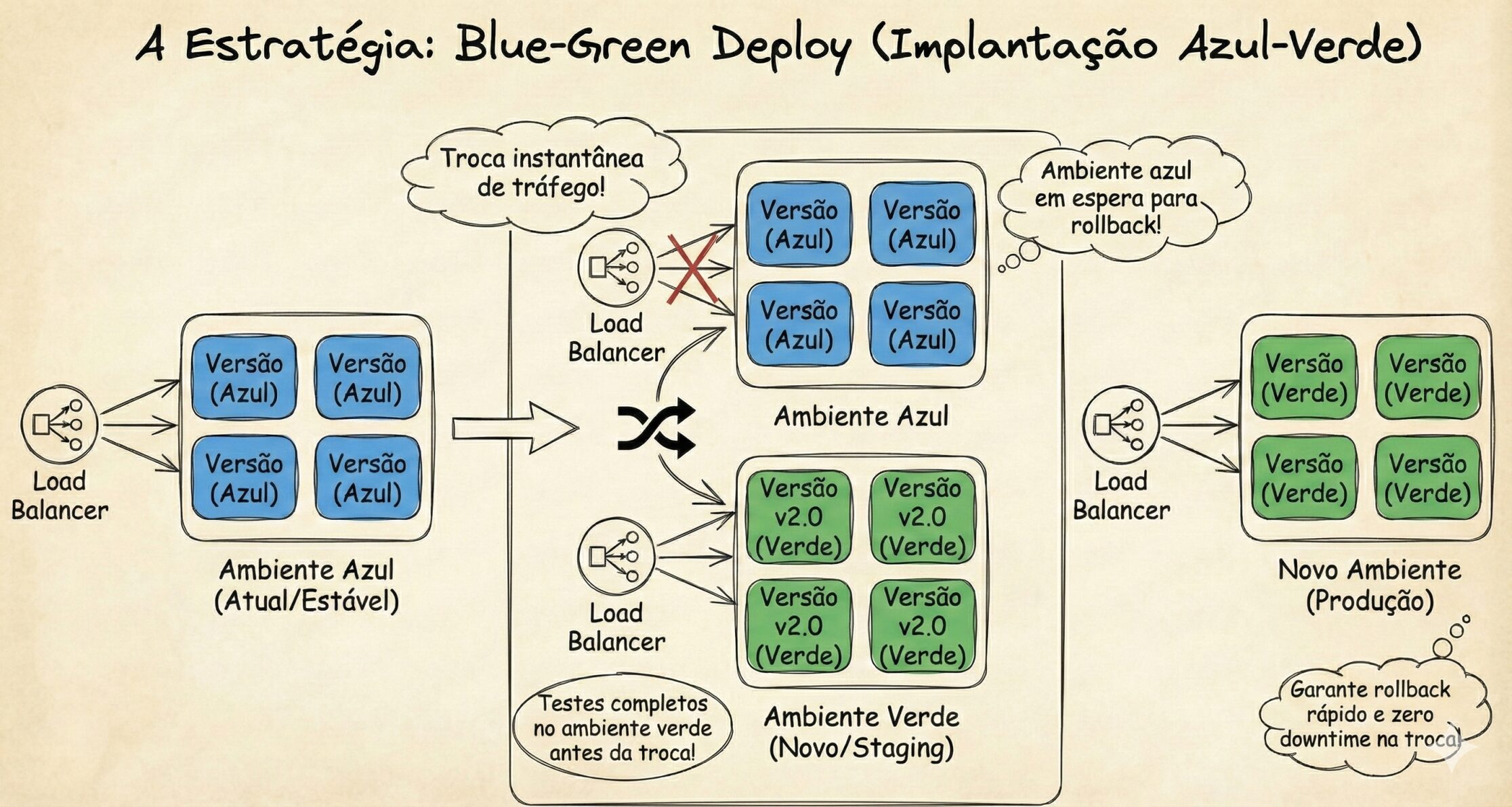
2. Blue/Green Deployment: A Segurança Máxima
Para sistemas críticos (bancos, checkouts, saúde), esta é a estratégia principal.
Como funciona: Você duplica sua infraestrutura.
- Blue (Infraestrutura Atual): O ambiente que está recebendo 100% do tráfego dos usuários.
- Green (Infraestrutura Nova): Uma cópia exata da infraestrutura onde você fará o deploy da nova versão.
O Truque: Ao ser criado, ambiente Green ainda está invisível para o público, mas acessível para os QAs e Devs. Eles podem testar em produção real, sem (ou com poucos) riscos.
A Troca (The Switch): Quando tudo está validado, você vai no Load Balancer ou DNS (depende de como funciona seu caso) e muda o apontamento. O tráfego passa instantaneamente do Blue para o Green.
Vantagem: Rollback instantâneo. Deu problema? Volta a chave para o Blue em 1 segundo.
O Preço: Exige o dobro da infraestrutura durante o deploy (por algum tempo). Pode parecer caro, mas dependendo do custo do sistema fora do ar, pode haver alguma situação que vai tornar isso tudo barato. E o “caro” pode ser bem relativo, dependendo do tempo e tamanho da infraestrutura duplicada.
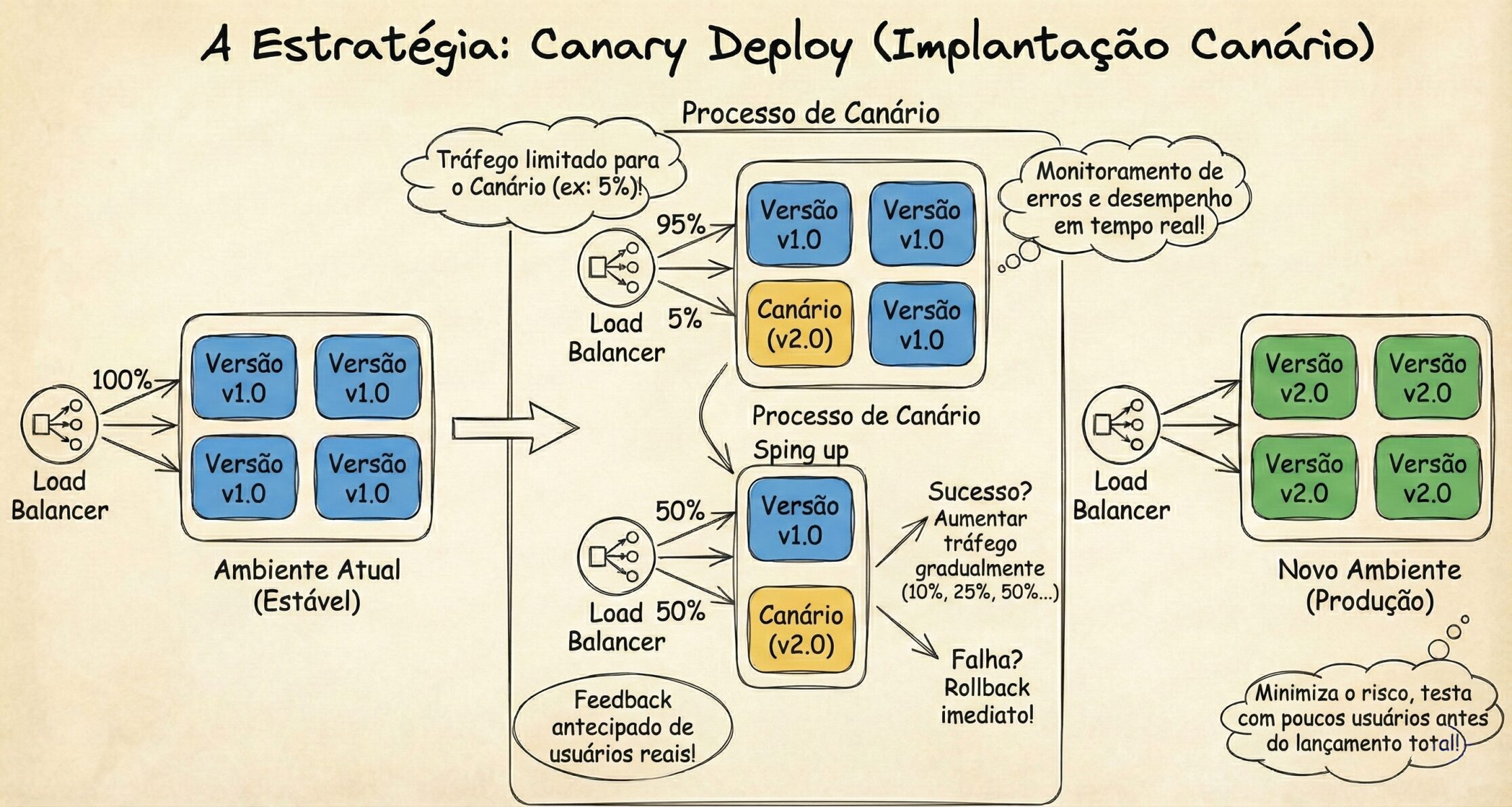
3. Canary Release: O Teste Estatístico
Baseado na antiga prática dos mineradores de levar um canário para a mina de carvão. Se o canário parasse de cantar ou desmaiasse, havia gás carbônico ou metano, inodoros, e os mineradores fugiam.
Como funciona: Em vez de ir trocando tudo de uma vez, você libera a versão nova apenas para uma pequena parte dos usuários (ex: 5%).
Monitoramento: Aqui a Observabilidade (tema do futuro Artigo 6) é vital. Você deve comparar as métricas para tomar a decisão de seguir aumentando a carga ou realizar um rollback. Por exemplo: “A taxa de erro nos 5% (v2) é maior que nos 95% (v1)?”
O Truque: Se houverem erros importantes: O sistema reverte o tráfego da v2 automaticamente. Apenas 5% dos usuários foram afetados. Se der certo: Aumenta-se gradualmente a carga: 10% -> 25% -> 50% -> 100%.
Diferença para Feature Flags: O Canary é controlado na infraestrutura (Load Balancer/Service Mesh) e testa a versão do container. Feature Flags controlam funcionalidades no código. Grandes projetos geralmente usam os dois juntos.
⚠️ O Segredo Técnico: Graceful Shutdown
Não adianta ter a melhor estratégia de orquestração se a sua aplicação for “assassinada” e deixar todos os processos terminarem no além.
Quando o Kubernetes ou o Load Balancer decide matar um container antigo, ele envia um sinal de término (SIGTERM), que informa ao kernel que ele devem encerrar as atividades e desligar. A alternativa é o SIGKILL, que simplesmente mata o sistema operacional imediatamente.
Encerramento Abrupto (Hard Shutdown): Morre instantaneamente. Se ela estava processando um pagamento ou salvando um arquivo, o usuário recebe um erro.
Encerramento “Gracioso” (Graceful Shutdown): Ao receber o sinal, ela:
- Para de aceitar novas conexões.
- Termina de processar as requisições que já estavam em andamento.
- Só então se desliga (ou espera o SIGKILL forçado após 30s).
Sem Graceful Shutdown, qualquer deploy, mesmo Blue/Green, vai gerar erros 502/504 para uma parcela de usuários azarados.
🐘E o Banco de Dados? O Elefante na Sala (sem trocadilho…)
Tudo o que falamos até agora funciona lindamente para o código (que é stateless). Mas o banco de dados tem estado (stateful). Você não pode simplesmente fazer um “Blue/Green” do banco de dados de produção de 10TB.
Se a sua versão nova (v2) faz uma alteração na estrutura do banco (ex: renomear uma coluna de endereco para endereco_completo), e você faz um Rolling Update:
- A migration roda e renomeia a coluna.
- Os containers v2 sobem e funcionam.
- Mas os containers v1 (que ainda estão servindo usuários) quebram imediatamente, pois eles ainda buscam pela coluna endereco que sumiu.
Compatibilidade Retroativa (Backward Compatibility)
Em arquiteturas de alta disponibilidade, nunca fazemos alterações destrutivas no banco no mesmo deploy do código. Seguimos o padrão Expand and Contract (Expandir e Contrair):
Deploy 1 (Expandir): Você cria a nova coluna endereco_completo, mas não apaga a antiga. O banco agora suporta tanto a v1 quanto a v2. Talvez seja necessário fazer todas as alterações (inserts, updates e deletes) concomitantemente nas duas colunas via trigger ou uma feature flag. Cada caso vai ter que ser avaliado.
- Deploy 2 (Código): Você sobe a aplicação v2, que grava na coluna nova. Se precisar de rollback, a coluna antiga ainda está lá, intacta.
- Deploy 3 (Contrair): Só depois que a v2 está estável há dias e a v1 não existe mais, você roda uma limpeza para apagar a coluna antiga endereco.
E o Rollback? É ruim admitir, mas em grandes projetos, quase nunca se faz rollback de banco de dados (voltar o backup ou desfazer migration). É arriscado demais perder dados de transações que ocorreram no meio tempo. A estratégia é: O banco de dados só “anda para frente” (Roll Forward). Se o código quebrar, você reverte o código (containers), e o banco deve ser robusto o suficiente para aceitar o código velho de volta sem reclamar. Para isso fluir sem dor de cabeça, é necessária a supervisão técnica de LTs e devs sêniores em cada review de código e contexto, além de políticas claras sobre atualizações de bancos de dados. Mais um aspecto cultural a ser trabalhado com a equipe.
🏁 Resumo da Etapa
O deploy moderno é um exercício de gestão de risco, tráfego e dados. Vimos que não basta copiar arquivos; precisamos orquestrar a troca dos containers (Rolling/Blue-Green), garantir que a aplicação saiba morrer com classe (Graceful Shutdown) e, crucialmente, que o banco de dados nunca quebre a versão anterior.
⏭️ No próximo artigo: O processo de desenvolvimento e CI/CD já estão azeitados. Mas onde o código roda? Vamos falar da “Infraestrutura como Código” (IaC) e por que trabalhar no console web da AWS ou Azure é um pecado capital em grandes empresas.
Deixe um comentário